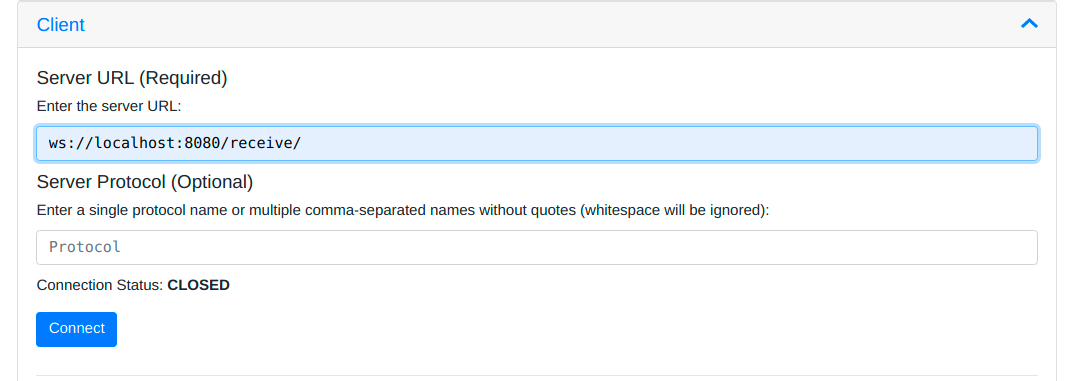
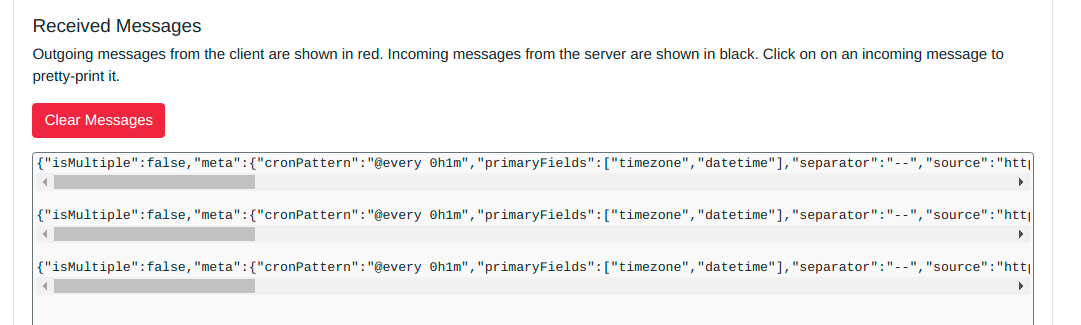
This is a simple app that queries a given REST API at a given interval (including once at the start), transforms the data returned into client-style JSON and pushes it over to a PubSubQ instance. It handles REST APIs that return XML, JSON, or CSV.
What is Client-style JSON?
Client-style JSON is the kind of JSON where a given dataset is represented by an object instead of an array.
The object's keys are composite keys constructed from a list of primary key fields.
The object's values the records.
This has the advantage of ensuring client apps don't do any extra processing in case they are to display the data in list-like components like charts, tables, lists etc.
The client-style JSON can also have multiple datasets but they also will be in an object where the keys are the names of the datasets and the values are the client-style JSON for those datasets.
Client-style JSON has three main keys:
- "data" - where the data is found
- "meta" - where any extra information like the source, the primary keys used etc. are found.
- "isMultiple" - to distinguish between data that has multiple datasets and data that has a single dataset
Here are examples of client-style JSON
{
"isMultiple": false,
"meta": {
"source": "https://example.com/volume",
"primaryFields": ["date", "time"],
"separator": "--",
"cron": "@every 1h30m"
},
"data": {
"2021-07-23--11:00:00 GMT": {
"amount": 90.8,
"date": "2021-07-23",
"time": "11:00:00 GMT",
},
"2021-07-23--12:00:00 GMT": {
"amount": 900.8,
"date": "2021-07-23",
"time": "12:00:00 GMT",
},
"2021-07-23--13:00:00 GMT": {
"amount": 0.6,
"date": "2021-07-23",
"time": "13:00:00 GMT",
},
"2021-07-23--14:00:00 GMT": {
"amount": 76.4,
"date": "2021-07-23",
"time": "14:00:00 GMT",
}
}
}
{
"isMultiple": true,
"meta": {
"source": "https://example.com/purchases",
"primaryFields": ["date", "time"],
"groupBy": "data_type",
"separator": "&^",
"cronPattern": "@every 0h30m"
},
"data": {
"volume": {
"2021-07-23&^11:00:00 GMT": {
"amount": 90.8,
"date": "2021-07-23",
"time": "11:00:00 GMT",
"data_type": "volume"
},
"2021-07-23&^12:00:00 GMT": {
"amount": 900.8,
"date": "2021-07-23",
"time": "12:00:00 GMT",
"data_type": "volume"
},
},
"price": {
"2021-07-23&^11:00:00 GMT": {
"price": 3000,
"date": "2021-07-23",
"time": "11:00:00 GMT",
"data_type": "volume"
},
"2021-07-23&^12:00:00 GMT": {
"price": 4500,
"date": "2021-07-23",
"time": "12:00:00 GMT",
"data_type": "volume"
}
}
}
}
How Are Data Pipelines Setup?
We use a JSON configuration file to define the data pipelines. By default, that configuration file is a JSON file called "restieConfig.json" expected to be found in the same folder as the running app.
However, any JSON configuration file of whatever name and path can be used. Its full path just needs to be passed to the app when running using the --config (or -c) flag e.g.
./restie run --config /home/admin/configs/etl.json
Here is a sample configuration file for Restie.
{
"pipelines": [
{
"name": "volume_pipeline",
"source": "https://example.com/volume",
"sourceType": "XML",
"httpMethod": "GET",
"isMultiple": false,
"cronPattern": "@every 1h30m",
"timestampPattern": "YYYY-MM-DDThh:mm:ssZ",
"datePattern": "YYYY-MM-DD",
"timezone": "Africa/Cairo",
"dataPath": ["response", "responseBody", "responseList"],
"recordTag": "record",
"primaryFields": ["date", "time"],
"separator": "--",
"queryParams": {
"startDatetime": "NOW - 0Y0M0D0h0m0s0ms",
"endDatetime": "NOW + 0Y0M0D1h0m0s0ms",
"APIKey": "uyfoafayreyruhererhjkahjkhs",
},
"headers": {
"Authorization": "Bearer uyfoafayreyruhererhjkahjkhs",
"Host": "https://example.com"
},
"postData": {},
"pubSubQUrl": "ws://localhost:8005",
"pubSubQAuthData": {
"username": "johndoe",
"password": "badguyi"
},
},
{
"name": "purchases_pipeline",
"source": "https://example.com/purchases",
"sourceType": "JSON",
"httpMethod": "POST",
"isMultiple": true,
"groupBy": "data_type",
"dataPath": ["response", "responseBody", "responseList"],
"recordTag": "",
"cronPattern": "@every 0h30m",
"timestampPattern": "YYYY-MM-DDThh:mm:ss",
"datePattern": "YYYY-MM-DD",
"timezone": "Africa/Kampala",
"primaryFields": ["date", "time"],
"separator": "&^",
"queryParams": {
"startDatetime": "NOW",
"endDatetime": "NOW + 0Y0M0D0h30m0s0ms",
},
"headers": {
"Authorization": "Bearer uyfoafayreyruhererhjkahjkhs",
"Content-Type": "application/json"
},
"postData": {
"endDate": "TODAY + 0Y0M3D",
"endMonth": "CURRENT_MONTH + 0Y2M",
"endYear": "CURRENT_YEAR + 5Y",
},
"pubSubQUrl": "ws://localhost:8006"
}
]
}
The possible configuration properties can be broken down as follows:
| Config Property |
Type |
Required |
Description |
| name |
text (no spaces, single line) |
Yes |
The name of the pipeline. It will be the same as the message type published to in the PubSubQ |
| source |
URL |
Yes |
The REST API endpoint from which to get the data. No query parameters should be part of it |
| sourceType |
text: any of "XML", "CSV", or "JSON" |
Yes |
The type of response to be expected from the REST API endpoint. |
| httpMethod |
text: any of "GET", "POST" |
Yes |
The HTTP method the REST API endpoint is to be accessed by |
| isMultiple |
boolean (true or false) |
Yes |
Whether the data returned by the endpoint has multiple datasets in it basing on the perspective of the client. For example a client might need data grouped by author, and so the returned data will have a dataset for each author. |
| groupBy |
text (no spaces, single line) |
Yes if isMultiple is true, No otherwise |
The field on each data record to use to group the data into multiple datasets. For the example above, it might be "authorId" |
| cronPattern |
text of "@each {}h{}m" or "* * * * * * *" form. See below for more details |
Yes |
The Cron setting to control when this data pipeline is to be run, repetitively. The app has an internal cron runner. |
| timestampPattern |
text with YYYY, MM, DD, hh, ss, mm, zz, z, or Z |
Yes |
The timestamp pattern to use when constructing any time-based query params, post data or headers on each cron run. There is a special config syntax for such time-based data. See below. |
| datePattern |
text with YYYY, MM, DD |
Yes |
The date pattern to use when constructing any date-based query params, post data or headers on each cron run. There is a special config syntax for such time-based data. See below. |
| timezone |
text (valid timezone names) |
Yes |
The timezone in which the cron is to be run |
| dataPath |
list of text |
Yes if sourceType is XML, No otherwise |
The list of fields to follow along XML or JSON REST responses so as to get to the actual data. |
| recordTag |
text |
Yes if sourceType is XML, No otherwise |
The name of the XML tag that holds each individual record. |
| primaryFields |
list of text |
Yes |
The list of fields that would be used to collectively uniquely identify a given record in a dataset. |
| separator |
text |
No |
The string to be used when creating a single key out of the primary key values of a given record so as to create a unique key for the Client-style JSON |
| headers |
map of text keys and text values |
No |
The headers to be sent along during the REST API request. Some headers may be time-dependent or date-dependent. To cater for those, there is a special syntax to use in the configuration. See below. |
| queryParams |
map of text keys and text values |
No |
The query parameters to be sent along during the REST API request. Some query parameters may be time-dependent or date-dependent. To cater for those, there is a special syntax to use in the configuration. See below. |
| postData |
map of text keys and any primitive type values e.g. integers, strings |
No |
The data to be sent in the POST body if httpMethod is "POST". Some properties in this data may be time-dependent or date-dependent. To cater for those, there is a special syntax to use in the configuration. See below. |
| pubSubQUrl |
Websocket URL |
Yes |
The websocket base URL of the PubSubQ instance to which this Restie app will publish its data so that the data can be availed in realtime to all other apps that need it. |
| pubSubQAuthData |
map of text keys and text values |
No |
The auth data to be passed to a secured PubSubQ instance to authenticate with it before publishing to it. |
How Do We Configure Time-Dependent and Date-Dependent Headers, Query Parameters or Post Data
We understand that certain REST API requests might have headers, POST data or query parameters that depend on time. We have provided an option to have such values in the form below (the square brackets mean the things inside are optional)
KEYWORD [OPERATOR OPERAND]
The KEYWORD can be any of: NOW, CURRENT_QUARTER_HOUR, CURRENT_HALF_HOUR, CURRENT_HOUR, TODAY, CURRENT_MONTH, CURRENT_YEAR
The optional OPERATOR can be any of: +, -
The optional OPERAND can be in the form (the square brackets mean the things inside are optional):
[<Years>Y][<months>M][<days>D][<hours>h][<minutes>m][<seconds>s][<mlliseconds>ms]
e.g.
For: 20 years, 5 months, 2 days, 60 hours, 45 minutes, 13 seconds and 67 milliseconds
For: 20 years and 5 months
A sample configuration of a REST API endpoint that always sends the current half hour (current_half_hour), the start date (start_date) as the previous day's date and the end date (end_date) as the date of the day five days from now via query parameters might look something like:
Some required properties have been removed for brevity
{
"pipelines": [
{
"source": "http://example.com",
"timezone": "Africa/Kampala",
"httpMethod": "GET",
"queryParams": {
"current_half_hour": "CURRENT_HALF_HOUR",
"start_date": "TODAY - 1D",
"end_date": "TODAY + 5D"
}
}
]
}
If today were 2021-07-26 and the time now were 11:00:00EAT, the resulting URL would be:
http://example.com?current_half_hour=23&start_date=2021-07-25&end_date=2021-07-31
How Do We Configure the Timing of the Data Pipelines
We use the cronPattern property to control the time intervals when a given REST API endpoint is to be queried.
It deals with repetitive REST calls such as: "every Wednesday at 11:00 am EAT (*)", "every minute"
The cronPattern has two possible formats:
The ******* Pattern:
This is the usual "*****" pattern but with two extra "*" for second and year.
Note: It does not support the */number syntax e.g. */7
Note: day of week is from 0 (Sunday) to 6 (Saturday)
The pattern is of the form:
<second>|* <minute>|* <hour>|* <day>|* <month>|* <dayOfWeek>|* <year>|*
e.g.
For: every Wednesday at 11:00:05
A sample configuration can look like:
Some required properties have been left out for brevity
{
"pipelines": [
{
"name": "sample_pipeline",
"source": "http://example.com/api/v2",
"cronPattern": "5 0 11 * * 3 *"
}
]
}
The @every Pattern:
This is the simpler version of creating jobs that run say every hour or every minute or every second or every millisecond etc.
Note: The shortest interval is a millisecond
The pattern is of the form:
@every [<hours>h][<minutes>m][<seconds>s][<milliseconds>MS]
e.g.
For: every 2 and a half hours and 30 seconds and 3 milliseconds
For: every 3 seconds and 45 milliseconds
For: every hour
A sample configuration can look like:
Some required properties have been left out for brevity
{
"pipelines": [
{
"name": "sample_pipeline_2",
"source": "http://example.com/api",
"cronPattern": "@every 30m"
}
]
}